-

Administrator Guide
-
Collect Logs
-
Collect Logs: Apps & Services
- ESXi
- Routers network hardware
- Apple iOS and macOS
- Unix and BSD system logs
- C# and .NET (NLog)
- C# and .NET (log4net)
- Java logback
- Android
- Kubernetes cluster logging with rKubelog
- haproxy
- Advanced Unix logging tips
- Perl
- Windows
- Kubernetes
- Erlang
- Node.js
- Java log4j
- JavaScript
- Unicorn
- PHP
- Docker
- systemd
- Ruby on Rails
- MySQL
- Unix and BSD text log files (remote_syslog2)
- Redis
- Go
- Python
- Elixir
- IIS
- Embedded devices or proprietary systems
-
Collect Logs: Hosting Services
-
Collect Logs: Integrations
-
Manage Logs
- Groups
- Log flood detection
- Web Hooks
- Log colorization
- Linking to logs
- JSON search syntax
- Settings API
- Log destinations
- Alerts
- Command-line client
- Log filtering
- HTTP API
- Automatic S3 archive export
- Managing Senders
- Permanent log archives
- Mapping senders to groups
- Search syntax
- Click-to-search
- Log search API
- Event Viewer
-
Send Logs for Analytics
-
SolarWinds Users & Orgs
-
Support and Security
-
What's New
Hadoop and Hive: SELECT *
Step-by-step introduction to get interactive SQL query access to months of Papertrail log archives (using Hadoop and Hive).
For a quick start, see Log analytics with Hadoop and Hive.
Background
This article covers how to:
- load logs into a SQL-compatible system for ad-hoc analysis (Hive), accessible from your terminal
- extract important message-specific fields into separate columns, so they can be used in SQL queries. For example, the message
Request for /foo from 1.2.3.4 in 42 mscould become a row with columns containing/foo,1.2.3.4and42. This allows domain-specific reporting. - output reports to intermediate reporting tables or CSV suitable for business analysts and visualizations
Setup is typically 10-30 minutes.
No new software or local infrastructure is required, only basic familiarity with SQL. Hadoop can run on Amazon Elastic MapReduce (EMR) and S3, entirely within your Amazon Web Services account. We’ll show you how to get an account and provide quick step-by-step setup. Or to run Hadoop locally, we recommend Cloudera’s Distribution for Hadoop (CDH).
Note: Papertrail also provides a quick way to receive small volumes of events immediately or in an hourly or daily summary. See Web hooks.
Example uses
Basic:
SELECT source_name, COUNT(source_name) FROM events GROUP BY source_name
SELECT received_at, message FROM events GROUP BY source_nameAnd more sophisticated, breaking out message elements into columns:
SELECT AVERAGE(response_time) FROM request_events GROUP BY request_path
SELECT SUM(data_transferred) FROM api_logs GROUP BY account_id WHERE ds > '2011-01-01' AND ds < '2011-01-31'Because this analysis uses the Hive query language on Hadoop (Map/Reduce), very flexible queries are possible, usually with no knowledge of Hadoop or Hive.
Amazon EMR also works with other Hadoop tools like Pig and Hadoop Streaming (Python Dumbo, Ruby wukong, Perl Hadoop::Streaming).
Setup
Enable log archiving
Create an Amazon Web Services account if you don't have one. If you're using Papertrail for log aggregation and management, activate Papertrail's permanent log archives. Here's how.
Papertrail will upload a compressed log archive file to your S3 bucket. Login to the AWS Management Console, browse to your S3 bucket, and confirm that you see at least one datestamped item in papertrail/logs/.
Activate Amazon Elastic MapReduce (EMR)
In the AWS Management Console, click the Elastic MapReduce tab and enable it on your account. If you haven’t used EMR before, Amazon may take a few minutes to activate your account.
Create SSH key
Note: You can skip this if you use EC2 and already connect with a key pair.
Since we'll SSH into the EMR node, we need a key that the EMR node knows about. We'll let Amazon generate one. Login to the AWS Management Console and click the EC2 (not EMR) tab. Click "Key Pairs," then "Create Key Pair." Give it a name. Your browser will look like this:
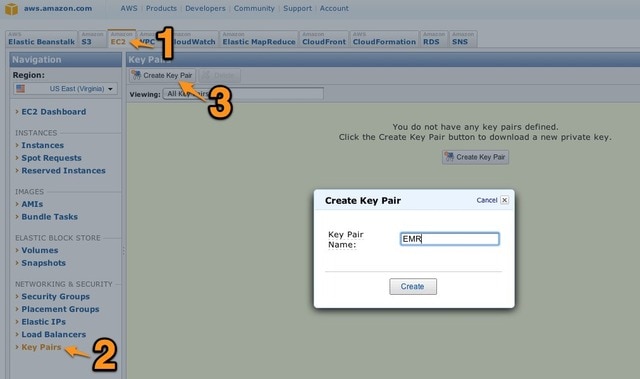
Click "Create." Amazon will create the key and your browser will download a .pem key file. We’ll use that key to SSH to the EMR node.
Start EMR node
Next, we'll setup a new EMR node. You can leave this running or shut it down when you're done.
Important: EMR runs in your AWS account, and Amazon will charge your credit card. Most jobs complete quickly - a few minutes to a few hours - but you are responsible for the payment, and for shutting the node down when you’re done.
Create cluster
In the AWS Console - EMR, click Create Cluster. Give this cluster a name, click No to disable Termination Protection, and un-check "Logging" to disable sending this EMR cluster’s logs to S3:
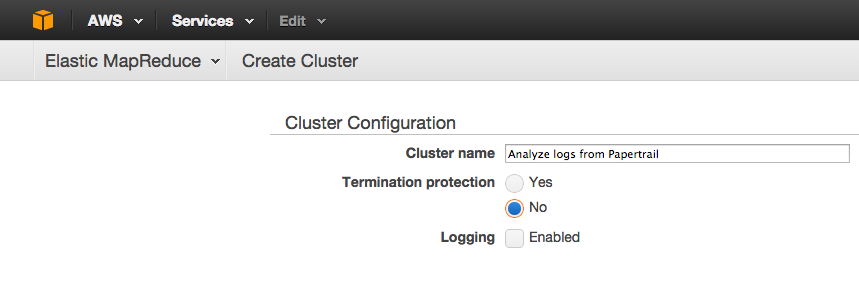
Configure cluster settings
Scroll to "Hardware Configuration" to configure the number and size of EMR nodes. If this is your first job and is for testing, consider changing the number of each role to 1 and the type to m1.medium.
Scroll to "Security and Access." Choose the EC2 Key Pair you created above. Strongly consider changing "IAM user access" to "No other IAM users" so that only your key pair has access.
Click "Create Cluster." The AWS console will take you to a page with the status of this cluster.
Load logs
Connect to EMR node
The EMR node will take a few minutes to start. On the AWS console cluster details page, when the "Hardware" section changes from "Provisioning" to "Running," the cluster is ready to be accessed.
"No active keys found for user account": If the status changes to "Terminating" with the error "No active keys found for user account," it means the AWS management console user needs an access keys. See this page to create an access key.
Once the cluster details page reports a status of "Running," look for the cluster's hostname. It is labeled "Master public DNS."
On your local system, navigate to the directory with the .pem key file
downloaded earlier. SSH to the cluster’s master public DNS hostname using
the downloaded .pem key. Use the SSH user hadoop. For example:
$ chmod 600 EMR.pem
$ ssh -i EMR.pem hadoop@ec2-84-73-110-156.compute-1.amazonaws.comYou should be logged in and sitting at the Linux shell for user hadoop. Type: hive and hit enter.
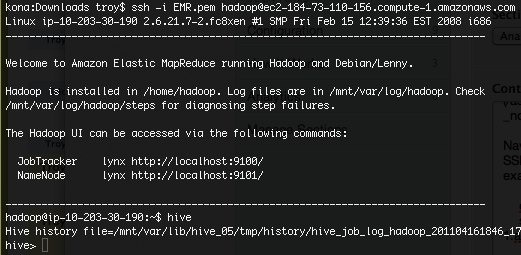
Load logs
Create a table for these events by pasting this command. Replace your-s3-bucket.yourdomain.com with the S3 bucket name that you configured Papertrail archives in. Paste this:
CREATE EXTERNAL TABLE events (
id bigint, received_at string, generated_at string, source_id int, source_name string, source_ip string, facility string, severity string, program string, message string
)
PARTITIONED BY (
dt string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
LOCATION 's3://your-archive-bucket/papertrail/logs/xyz';Replace your-archive-bucket/papertrail/logs/xyz with the bucket and path on Archives.
This may take a minute to complete. Finally, load the data by forcing Hive to update its metadata:
MSCK REPAIR TABLE events;If the MSCK REPAIR command isn’t found, as with older Hive versions on EMR, use this instead:
ALTER TABLE events RECOVER PARTITIONS;This command may also take a minute to complete. It only reads information about each log file, not file contents.
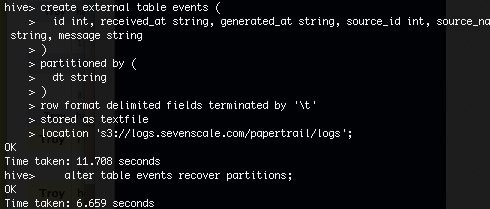
For more information, see Amazon's EMR with S3 doc.
Verify
To check the import worked, run a small example query:
SELECT * FROM events LIMIT 5;Analyze
You should now have interactive SQL-style access to all of your archived events. Try some queries:
SELECT COUNT(id) FROM events;
SELECT source_name, COUNT(source_name) FROM events GROUP BY source_name
SELECT received_at, message FROM events GROUP BY source_nameThese should start processing immediately and provide progress updates on the Hive console.
Report
The power of Hive is extracting, filtering, and reporting on contents of the log message. Hive supports using regular expressions and string functions to filter messages and turn part of the message into columns, so:
Request from 1.2.3.4 for /handler/path handed (200) (505ms)can be parsed into columns:
1.2.3.4, /handler/path, 200, 505Hive can also create ad-hoc tables containing the results from queries, which can then be used for second-level analysis.
We'll create a new table containing a few columns from the events table, plus a new extracted column (first_word). The new column will contain the first word of each line, matched with a regular expression. We can then use SQL functions on that column like any other.
Run:
CREATE TABLE events_first_word (
first_word string, id bigint, received_at string, source_name string, program string, message string
);
INSERT OVERWRITE TABLE events_first_word
SELECT regexp_extract(message, '(\\w+)', 1), id, received_at, source_name, program, message FROM events;We could run the same query for a single day's logs and only those containing a certain substring. Here's an example:
INSERT OVERWRITE TABLE events_first_word
SELECT regexp_extract(message, '(\\w+)', 1), id, received_at, source_name, program, message FROM events
WHERE dt='2011-05-25' AND message LIKE '%GET%';The table will be created on the EMR node's HDFS partition instead of in S3. Views can also be created (and use no storage at all).
Hive: SHOW/DESCRIBE commands, functions/operators, full manual
Shut down EMR node
When you're done, login to the AWS Management Console Elastic MapReduce tab, choose this job flow, and click Terminate. Make sure it disappears from the job list.
The scripts are not supported under any SolarWinds support program or service. The scripts are provided AS IS without warranty of any kind. SolarWinds further disclaims all warranties including, without limitation, any implied warranties of merchantability or of fitness for a particular purpose. The risk arising out of the use or performance of the scripts and documentation stays with you. In no event shall SolarWinds or anyone else involved in the creation, production, or delivery of the scripts be liable for any damages whatsoever (including, without limitation, damages for loss of business profits, business interruption, loss of business information, or other pecuniary loss) arising out of the use of or inability to use the scripts or documentation.